2019 October 29 python, opencv
图像识别初学
图像识别初学
- 想要将每年的工作日历中的非工作日或者增加的工作日通过图像识别转化为文本信息,并链接到日历中生成提醒
- 工作日历中的放假日期用绿色表示,公司特别增加的非工作日用蓝色表示,而增加的上班日期用红色表示
- 这样用RGB进行每个月份的过滤是最简单的。但是问题是每一个月份都需要进行3次过滤,并进行文字的汇总。
- 文字的汇总本来是想要用tesseract来进行的,但是发现识别不出来,莫名的。可能是参数设定的不对导致的。
过程
- 首先是将原始的工作日历按照月份进行切割,这样可以比较小块的进行识别,并且识别出来的信息对应到该月份,避免了以后识别时日期对应的错误哦
- 切割(有手动版的和自动版的,自动版就是用opencv获得图片的长,宽,然后按照数据运算,切分成长多少,宽多少的块。但是有个问题就是图片中有除了想要的内容外的其他的文字,这些区域需要割掉。下面的是手动版的,精确一些)
import itertools
x0="a:b"
x1="c:d"
x2="e:f"
x3="g:h"
y0="i:j"
y1="k:l"
y2="m:n"
listx=[x0,x1,x2,x3]
listy=[y0,y1,y2]
listxy=itertools.product(listx,listy)
print(listxy)
('a:b', 'i:j')
('a:b', 'k:l')
('a:b', 'm:n')
('c:d', 'i:j')
('c:d', 'k:l')
('c:d', 'm:n')
('e:f', 'i:j')
('e:f', 'k:l')
('e:f', 'm:n')
('g:h', 'i:j')
('g:h', 'k:l')
('g:h', 'm:n')
- RGB过滤
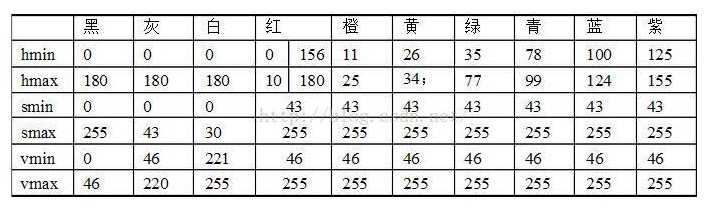
import cv2
import numpy as np
img = cv2.imread("cropped1.jpg")
lower_green = np.array([35, 43, 46]) #这些值来自于上面的图表
high_green = np.array([77, 255, 255])
hsv = cv2.cvtColor(img, cv2.COLOR_RGB2HSV) #将rgb值转为hsv值
mask = cv2.inRange(hsv, lower_green, high_green) #设定蒙层
cv2.imshow('mask', mask)
cv2.imwrite("green.jpg", mask) #应用蒙层,保存图片
- 识别